Prompter
Learn about our prompter operator
Output: Text
A prompt template serves as a pre-configured piece of text used to instruct a large language model (LLM). It acts as a structured query or input that guides the model in generating the desired response.
LLMs are trained on massive datasets of text and code, and they can be used to perform a variety of tasks, including text generation, question answering, translation, summarization, text completion, and more.
LLMs are designed to understand and generate text based on the instructions or prompts they receive. Prompting an LLM allows you to leverage the model’s pre-trained language capabilities and control its outputs so that it can deliver what is relevant to your needs.
The quality and relevance of the generated texts depend on the specific wording and context of the prompt. Prompts can be structured in various ways, and their effectiveness often depends on how well they convey the desired task or instruction to the model.
There are several prompting techniques you can use.
Zero-Shot Prompting
Zero-shot prompting leverages the model's inherent language understanding to perform tasks without any specific labeled training data.
It simply requires providing a clear prompt for the LLM to generate relevant responses. The LLM is then able to use its pre-trained knowledge to complete the task.
Let’s demonstrate how you can create a zero-shot prompter on the workflow builder for a text classification task.
Your prompt template should include at least one instance of the placeholder {data.text.raw}. When you input your text data at inference time, all occurrences of {data.text.raw} within the template will be replaced with the provided text.
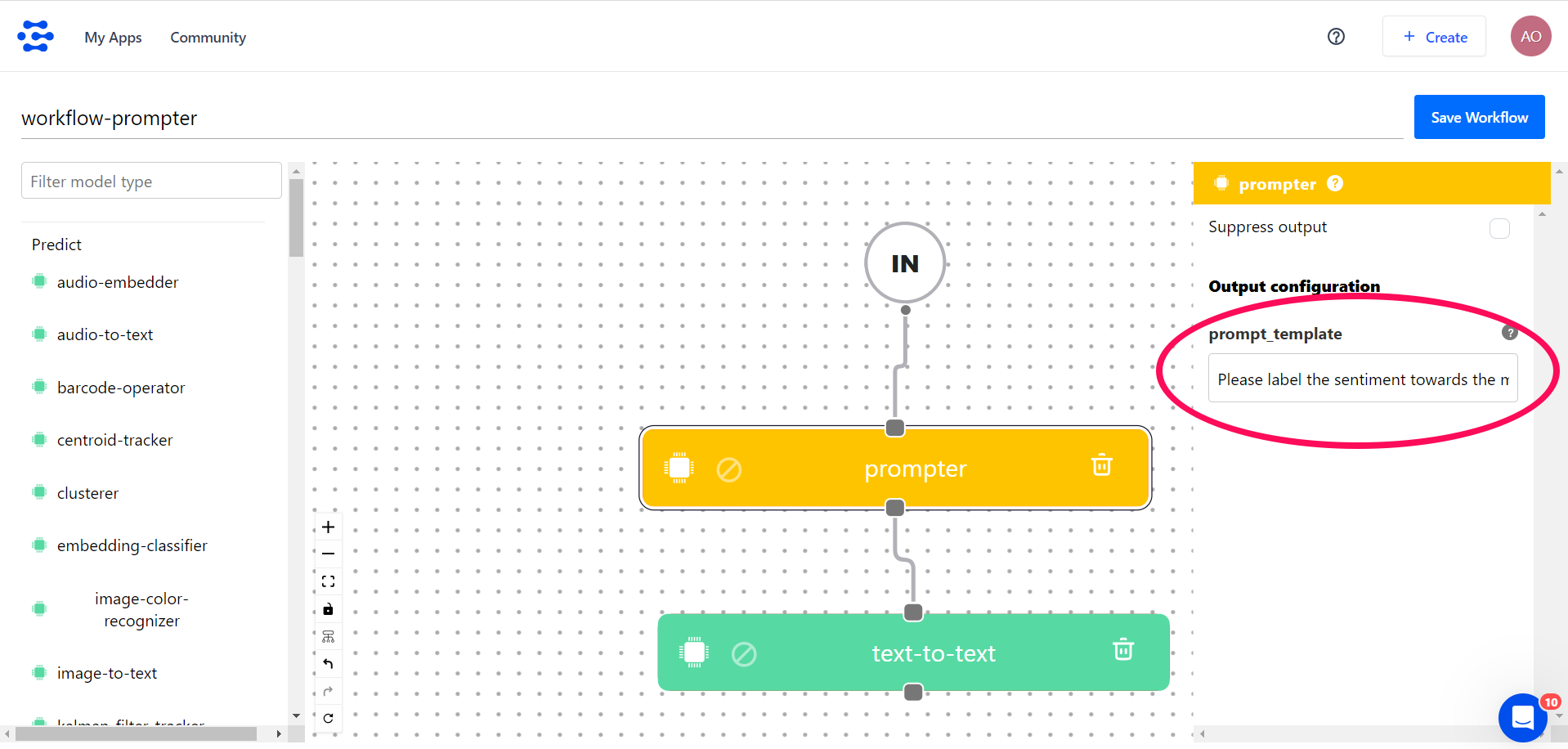
1. Search for the Prompter template option in the left-hand sidebar of the workflow builder and drag it onto the empty workspace.
2. Use the pop-up that appears on the right-hand sidebar to define the template text. For this example, let’s use the following text:
Please label the sentiment towards the movie of the given movie review. The sentiment label should be "positive" or "negative". ### Text: {data.text.raw} ### Sentiment:
Note that:
- The template text is a single-line statement.
- We included the
{data.text.raw}placeholder to meet the requirements of the Prompter template. - We placed the instructions at the beginning of the template text and used the "###" delimiter to separate the instruction and context. The delimiter is important when giving instructions to llms because it signifies the beginning and end of different sections within the text. This ensures clarity and facilitates easy parsing and processing during the prediction phase.
3. You can then connect the prompter model to a text-to-text model like GPT-4.
4. Save your workflow.
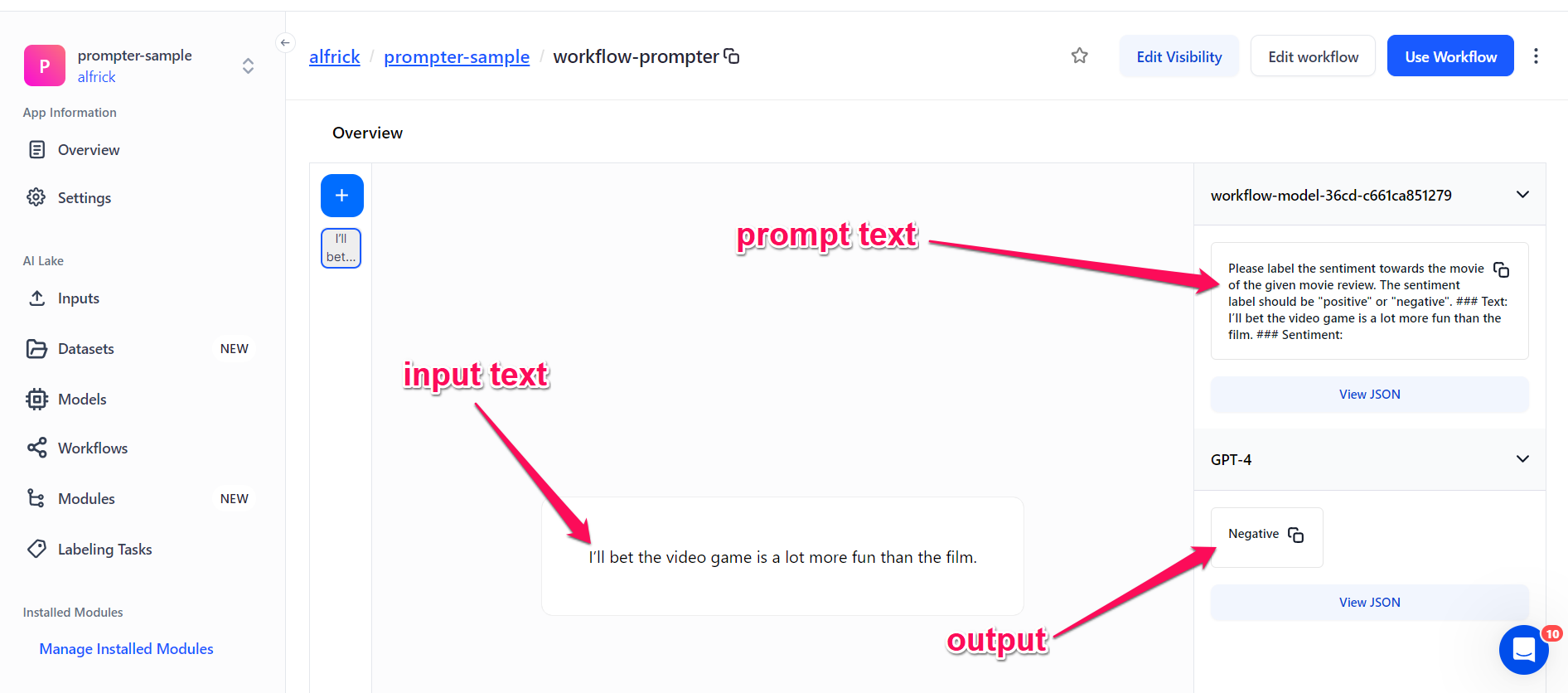
To observe it in action, navigate to the workflow's individual page and click the + button to input your text.
For example, you could input the following as your input text:
I’ll bet the video game is a lot more fun than the film
Click the Submit button.
Once the model has completed processing your input, you'll see the results, starting with the earlier template text, now adapted to your input.
In this case, the prompt text becomes:
Please label the sentiment towards the movie of the given movie review. The sentiment label should be "positive" or "negative". ### Text: I’ll bet the video game is a lot more fun than the film. ### Sentiment:
And the output becomes:
Negative
Note that in the above zero-shot prompt, we did not give the model any examples of text alongside their classifications. The model already knows what "sentiment" means without needing any extra information—that's how its zero-shot abilities work.
Few-Shot Prompting
In few-shot prompting, the large language model is given a limited number of examples or "shots" to adapt to a particular task. With just a few examples, it can perform more specialized tasks that require specific context or knowledge.
This is in contrast to zero-shot prompting, which does not require any examples. Few-shot prompting is often used for more complex tasks where zero-shot prompting is not sufficient.
For example, few-shot prompting can be used to train an LLM to classify new types of data, translate languages that it has not been trained on, or generate different creative text formats.
Let’s demonstrate how you can create a few-shot prompter on the workflow builder for a text classification task.
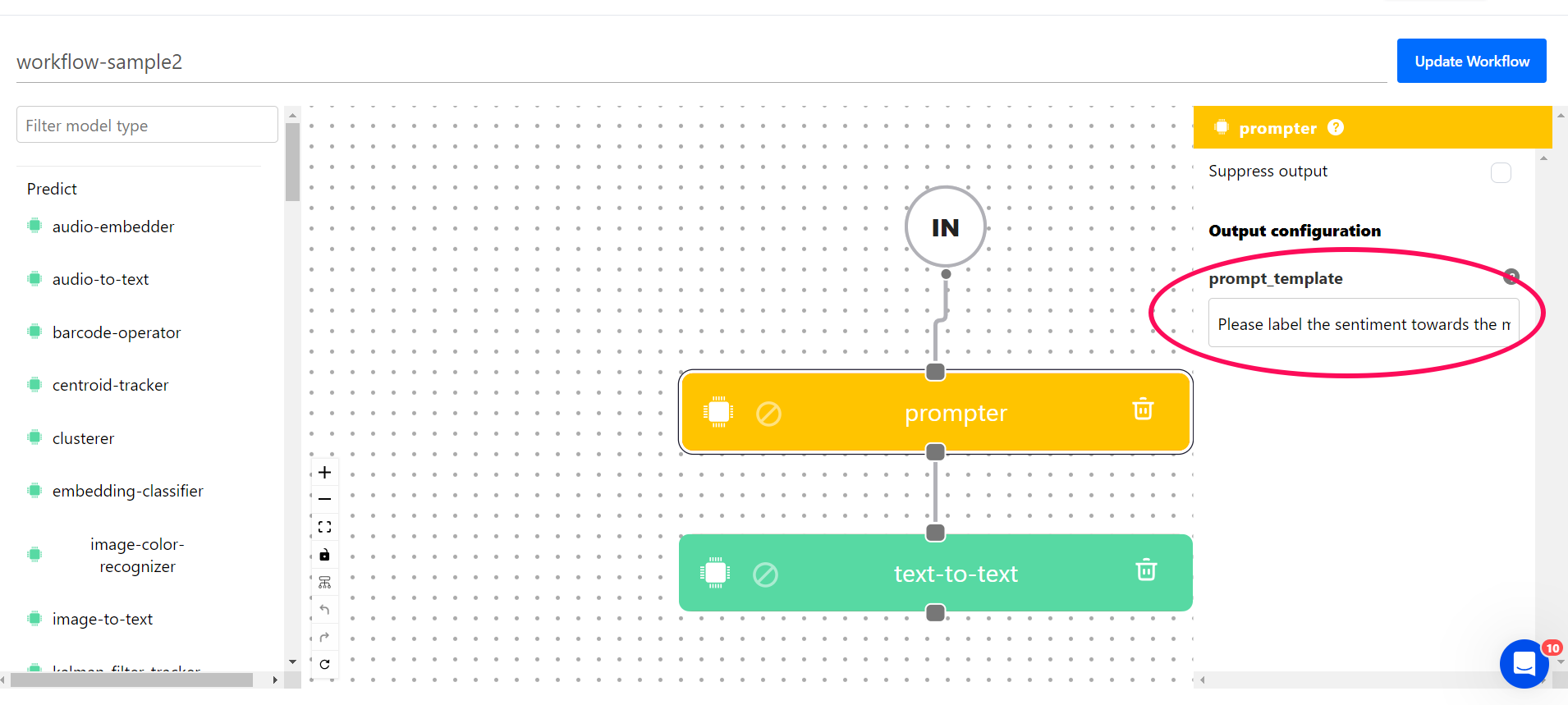
1. Search for the Prompter template option in the left-hand sidebar of the workflow builder and drag it onto the empty workspace.
2. Use the pop-up that appears on the right-hand sidebar to define the template text.
For this example, let’s use the following text:
Please label the sentiment towards the movie of the given movie review. The sentiment label should be "positive" or "negative". ### Text: (lawrence bounces) all over the stage, dancing, running, sweating, mopping his face and generally displaying the wacky talent that brought him fame in the first place. ### Sentiment: positive. ### Text: Despite all evidence to the contrary, this clunker has somehow managed to pose as an actual feature movie, the kind that charges full admission and gets hyped on tv and purports to amuse small children and ostensible adults. ### Sentiment: negative. ### Text: For the first time in years, de niro digs deep emotionally, perhaps because he's been stirred by the powerful work of his co-stars. ### Sentiment: positive. ### Text: {data.text.raw} ### Sentiment:
Note that just like in the zero-shot prompting example above, we included the {data.text.raw} placeholder and the "###" delimiter in the template text.
3. You can then connect the prompter model to a text-to-text model like GPT-4.
4. Save your workflow.
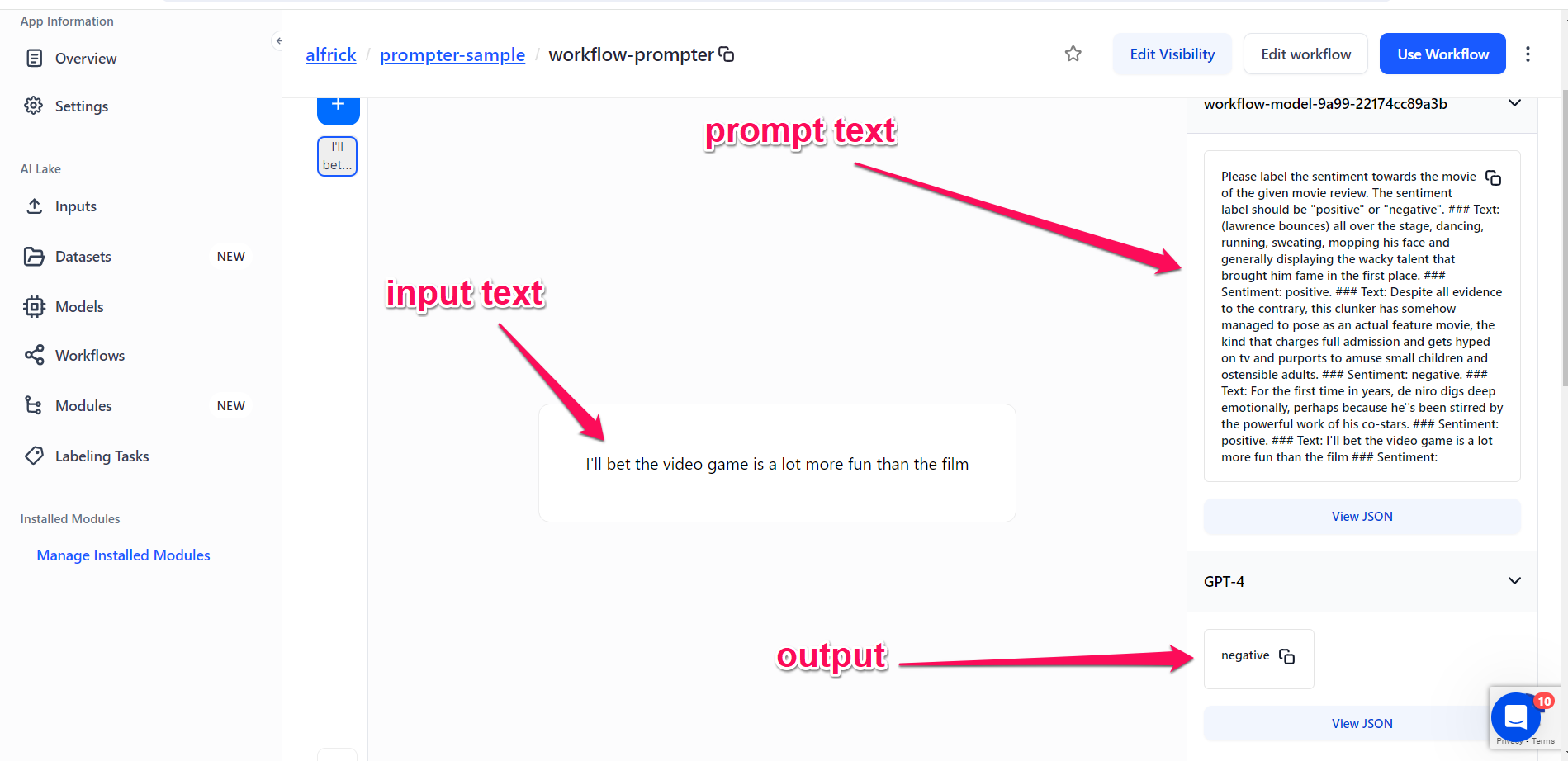
To observe it in action, navigate to the workflow's individual page and click the + button to input your text.
For example, you could input the following as your input text:
I'll bet the video game is a lot more fun than the film
Click the Submit button.
Once the model has completed processing your input, you'll see the results, starting with the earlier template text, now adapted to your input.
In this case, the prompter text becomes:
Please label the sentiment towards the movie of the given movie review. The sentiment label should be "positive" or "negative". ### Text: (lawrence bounces) all over the stage, dancing, running, sweating, mopping his face and generally displaying the wacky talent that brought him fame in the first place. ### Sentiment: positive. ### Text: Despite all evidence to the contrary, this clunker has somehow managed to pose as an actual feature movie, the kind that charges full admission and gets hyped on tv and purports to amuse small children and ostensible adults. ### Sentiment: negative. ### Text: For the first time in years, de niro digs deep emotionally, perhaps because he''s been stirred by the powerful work of his co-stars. ### Sentiment: positive. ### Text: I'll bet the video game is a lot more fun than the film ### Sentiment:
And the output becomes:
negative
Note that in the above few-shot prompt, we provided a few examples to guide the model to perform better. The demonstrations enabled in-context learning and acted as conditioning for successive examples in which we wanted the model to produce a response we desired.
The prompt template can be used for a variety of prompting methods. Let's delve into the descriptions of other different prompting techniques below.
Task-Specific Prompt
Here is an example of a text classification task with a task-specific prompt.
### Instruction: You are a customer service agent that is classifying emails by type. ### Input: <email> Hi -- My Mixmaster4000 is producing a strange noise when I operate it. It also smells a bit smoky and plasticky, like burning electronics. I need a replacement. </email> Categories are: (A) Pre-sale question (B) Broken or defective item (C) Billing question (D) Other (please explain) ### Assistant: My answer is (
Response:
B) Broken or defective item
Translation
Here is an example of a prompt text for a text translation task.
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: Translate the following phrase into French. ### Input: I miss you ### Response:
Response:
Je te manque
Pre-Encoded Knowledge QA
This involves utilizing the model's built-in pre-encoded knowledge base to respond to questions. The model is provided with a large collection of facts and relationships, which it uses to generate answers when given prompts or questions.
The pre-existing knowledge base equips the model with the ability to answer questions that demand a good understanding of the world.
Here is an example.
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: How did Julius Caesar die? ### Response:
Response:
Julius Caesar was assassinated by a group of up to 60 conspirators, led by Gaius Cassius Longinus and Marcus Junius Brutus, in the Senate House on the Ides of March (15 March) of 44 BC.
Close-Book QA
Close-book QA, also known as zero-shot QA, refers to the ability of an LLM to answer questions without access to any additional information or context beyond its internal knowledge base.
This stands in contrast to open-book QA, where the LLM can access and process external sources of information, such as documents, web pages, or knowledge bases.
Here is an example of a close-book QA with a model specific prompt.
Below is a document, followed by a question. Answer the question using information in the document. Respond using only information in the document below. Do not provide any other information that is not in the document. ### Input: {{DOCUMENT}} ### Instruction: {{QUESTION}} ### Response:
Text Extraction
Here is an example of a prompt for a text extraction task.
Please precisely copy any email addresses from the following text and then write them, one per line. Only write an email address if it's precisely spelled out in the input text. If there are no email addresses in the text, write "N/A". Do not say anything else. ### Input: {{TEXT}}. ### Response: