Multistage RAG Pipeline With DSPy
A tutorial by Mogith PN
Information retrieval techniques are growing at such a high pace that the quest for ever-more efficient and accurate systems continues. One such advanced methodology is called RAG. But what if we could push the boundaries of RAG even further? Today, we'll explore the exciting potential of multi-stage, multi-model RAG systems built with DSPy.
What is RAG?
Imagine a system that can sift through mountains of information, identify the most relevant bits, and then craft a clear and concise response to your query. That's the essence of RAG. It operates in three key stages:
- Retrieval: A
retrievermodule dives into a vast corpus of documents, seeking information related to the user's query. - Augmentation: The retrieved information changes at the
augmenterstage. This might involve filtering, summarising, or enriching the data with additional context. - Generation: Finally, the
generatorcreates a high-quality response that effectively addresses the user's query.
Visit this page to learn more about RAG.
But how will DSPy help RAG? Well, DSPy supercharges the process inside RAG. Traditional large language model applications often suffer from "fragility," requiring constant tweaking and adjustments when components change. DSPy framework optimizes the entire pipeline for your specific task, eliminating the need for repetitive manual fine-tuning whenever you modify a component. By integrating Clarifai with DSPy, you unlock access to Clarifai's powerful capabilities, including its ability to seamlessly call language models (LLMs) directly from the Clarifai platform. This integration empowers you to leverage Clarifai's application as a retriever specifically suited for vector search use cases.
Before we move on, install and setup some packages,
!pip install dspy-ai
!pip install clarifai
import os
#Replace your PAT
os.environ['CLARIFAI_PAT'] ="YOUR_PAT"
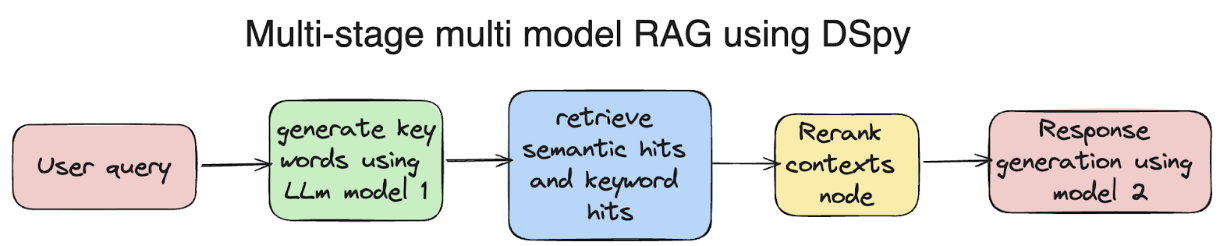
Now let's explore a possible implementation of a multi-stage, multi-model RAG system using DSPy. The motive of this experiment is to test the functionality of DSPy in building multi-stage systems in our RAG pipelines. Also, the compatibility to call and use multi models at different stages of the pipeline.
You can choose any LLM’s from this page.
import dspy
from dspy.retrieve.clarifai_rm import ClarifaiRM
MODEL_URL1 = "https://clarifai.com/mistralai/completion/models/mistral-7B-Instruct"
MODEL_URL2 = "https://clarifai.com/meta/Llama-2/models/llama2-7b-chat"
PAT = "**********"
USER_ID = "USER_ID"
APP_ID = "APP_ID"
mistral_llm=dspy.Clarifai(model=MODEL_URL1, api_key=PAT, n=1, inference_params={'temperature':0.6})
retriever_clarifai=ClarifaiRM(clarifai_user_id=USER_ID, clarfiai_app_id=APP_ID, clarifai_pat=PAT, k=5)
The GenerateAnswer class acts as a module within the DSPy pipeline. It takes the user's question and a relevant summary passage as inputs and then utilizes these to generate a concise answer.
class GenerateAnswer(dspy.Signature):
"""Think and Answer the questions based on the context provided."""
context = dspy.InputField(desc="may contain relevant summary passage about user query")
question = dspy.InputField(desc="User query")
answer = dspy.OutputField(desc="Generate a brief answer")
The GenerateKeywords class acts as a module within the DSPy pipeline. It takes the user's query as input and then generates a set of keywords that are closely related to the user's original query.
class GenerateKeywords(dspy.Signature):
"""Generate Key words for search, which will be related to user's query"""
query = dspy.InputField(desc="User query")
answer = dspy.OutputField(desc="3 Search Key words related to user query")
Why do we need a Re-ranker node?
We are retrieving contexts in 2 ways for our pipeline, starting with query search and keyword search, so our retrieved contexts will be quite huge for the model to handle.
The Reranker class acts as a quality control step within the DSPy pipeline. It takes a single retrieved document and the user's question as input. It then analyzes the document to assess how well it aligns with the user's query and provides a factual answer. The assigned rating (between 1 and 5) serves as an indicator of the document's relevance, potentially influencing how the retrieved information is used in subsequent stages of the pipeline.
DSPY Typed Predictors
In DSPy, typed predictors are a mechanism to enforce type constraints on the inputs and outputs of modules within a pipeline.
Click here to learn more about typed predictors.
First, let's define the output for the re-ranker model to be float using dspy typed predictors. And then we will create the Reranker class.
from pydantic import BaseModel, Field
class Reranker_Output(BaseModel):
score: float = Field(desc="A rating between 1 to 10 based on relevance and semantic match, IMPORTANT ! `float` . Nothing else return only float value as output.")
class Reranker(dspy.Signature):
"""Evaluate and rate the retrieved contexts based on their relevance in providing factual answers to user questions."""
context = dspy.InputField(desc="The context retrieved for answering question")
question = dspy.InputField(desc="User query")
rating = dspy.OutputField(desc="A rating between 1 to 5, IMPORTANT ! `float` . Nothing else return only float value as output.")
The Multi_RAG module constructs a multi-stage information retrieval system using DSPy. It extracts keywords to broaden the search, retrieves information using both the query and keywords, and then employs a separate language model to evaluate and rank the retrieved passages based on their relevance to the user's question. This multi-stage approach with distinct components allows for a more comprehensive and potentially more accurate information retrieval process.
import re
import functools
class Multi_RAG(dspy.Module):
def __init__(self):
super().__init__()
self.retrieve = dspy.Retrieve(k=5)
self.generate_kv = dspy.ChainOfThought(GenerateKeywords)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
self.generate_ratings = dspy.functional.TypedPredictor(Reranker)
def forward(self, question):
with dspy.context(lm=llama_llm):
kv = self.generate_kv(query=question).answer
print(f"Keywords extracted : {(kv)}")
context=[]
for search_query in [question,kv]:
results = self.retrieve(search_query).passages
context.extend(results)
context_rating = []
counter=0
for retrieved_context in context:
_rating={}
with dspy.context(lm=mistral_llm):
rating = self.generate_ratings(context=retrieved_context, question=question).rating
_rating['id'] = counter
_rating['score'] = rating
_rating['context'] = retrieved_context
counter+=1
print(f"Rating score for context {counter}: {rating}")
context_rating.append(_rating)
sorted_data = sorted(context_rating, key=lambda x: float(x['score'].score))
ranked_context = [passage["context"] for passage in sorted_data[:5]]
with dspy.context(lm=solar_llm):
prediction = self.generate_answer(context=str(ranked_context), question=question)
return dspy.Prediction(context=str(ranked_context), answer=prediction.answer)
And finally, we run a query on the Multi_Rag class,
my_question = "What are the potential risks associated with large language models (LLMs) according to the context information?"
# Get the prediction. This contains `pred.context` and `pred.answer`.
Rag_obj= Multi_RAG()
predict_response = Rag_obj(my_question)
# Print the contexts and the answer.
print(f"Question: {my_question}")
print(f"Predicted Answer: {predict_response.answer}")
Output
Keywords extracted : 1. "Misuse of large language models"
2. "Quality control in LLM outputs"
3. "Ethical implications of LLMs"
Rating score for context 1: score=1.0
Rating score for context 2: score=2.0
Rating score for context 3: score=2.0
Rating score for context 4: score=2.0
Rating score for context 5: score=2.0
Rating score for context 6: score=1.0
Rating score for context 7: score=1.0
Rating score for context 8: score=1.0
Rating score for context 9: score=1.0
Rating score for context 10: score=1.0
Question: What are the potential risks associated with large language models (LLMs) according to the context information?
Predicted Answer: The potential risks associated with large language models (LLMs) according to the context information include data leakage, performance inconsistency in tasks involving long textual contexts, and complexity in managing and utilizing extensive APIs.
Now we will compare the results obtained from Multistage DSPy RAG with a Vanilla RAG.
from clarifai.rag import RAG
rag_agent = RAG.setup(app_url="YOUR_APP_URL",
llm_url="https://clarifai.com/mistralai/completion/models/mistral-large", max_results=5)
n_rag_response = rag_agent.chat(messages=[{"role": "human", "content": "What are the potential risks associated with large language models (LLMs) according to the context information?"}])
print(n_rag_response[0]["content"])
Output
According to the context information provided, the potential risks associated with large language models (LLMs) are not explicitly stated. However, it is mentioned that there are risks associated with LLMs, and these risks are considered particularly important given their widespread use. Additionally, the context information highlights the importance of detecting, measuring, and mitigating biases in LLMs to prevent associated harms. It also mentions that a better understanding of bias metrics can help researchers better adapt and deploy LLMs. For more specific risks, one might need to refer to the cited source (Bender et al., 2021).
Then we can evaluate the performance of each RAG with the help of ragas library. Ragas is a valuable tool for assessing the performance of RAG pipelines.
Evaluation of Multistage DSPy RAG,
from datasets import Dataset
from ragas.metrics import faithfulness, answer_correctness
from ragas import evaluate
data_samples = {
'question': [benchmark_files["examples"][0]["query"]],
'answer': [predict_response.answer],
'ground_truth': [benchmark_files["examples"][0]["reference_answer"]]
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[answer_correctness])
score.to_pandas()
Output

from datasets import Dataset
from ragas.metrics import faithfulness, answer_correctness
from ragas import evaluate
data_samples = {
'question': [benchmark_files["examples"][0]["query"]],
'answer': [n_rag_response[0]["content"]],
'ground_truth': [benchmark_files["examples"][0]["reference_answer"]]
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[answer_correctness])
score.to_pandas()
Output

If you observe the values of answer_correctness for both RAGs, it can be seen that Multistage DSPy RAG outperforms Naive RAG. This Multi-Stage Multi-model RAG is a testament to the ability of DSPy framework and its modular nature of building different sets of stages within our LLM application.