Inference via UI
Generate model or workflow predictions on the UI
You can perform predictions using a model directly through the Clarifai's User Interface (UI) — no code required. This method is ideal for quick testing, demos, and visual validation of your model's performance.
You can simply upload an input (such as text, image, or video) and view the output predictions in real-time within an intuitive user experience.
The Clarifai Community platform offers a wide selection of the latest AI models that you can use to run inferences. You can also build and upload your own custom models and use them for predictions.
If you want to make predictions using Clarifai’s Compute Orchestration capabilities, you’ll need to set up a cluster, create a nodepool, and deploy your model to it. Once deployed, you can select this deployment for running inferences. If you don’t configure a custom deployment, the platform will use the default Clarifai Shared deployment where applicable, as explained here.
Generate Chat Predictions
The Clarifai platform lets you generate human-like text in a conversational format using large language models (LLMs). You simply provide text as input, known as a prompt, and these models generate coherent, context-aware text-based responses.
These models are ideal for tasks such as answering questions, summarizing content, generating code, or engaging in dialogue.
Step 1: Get a Model
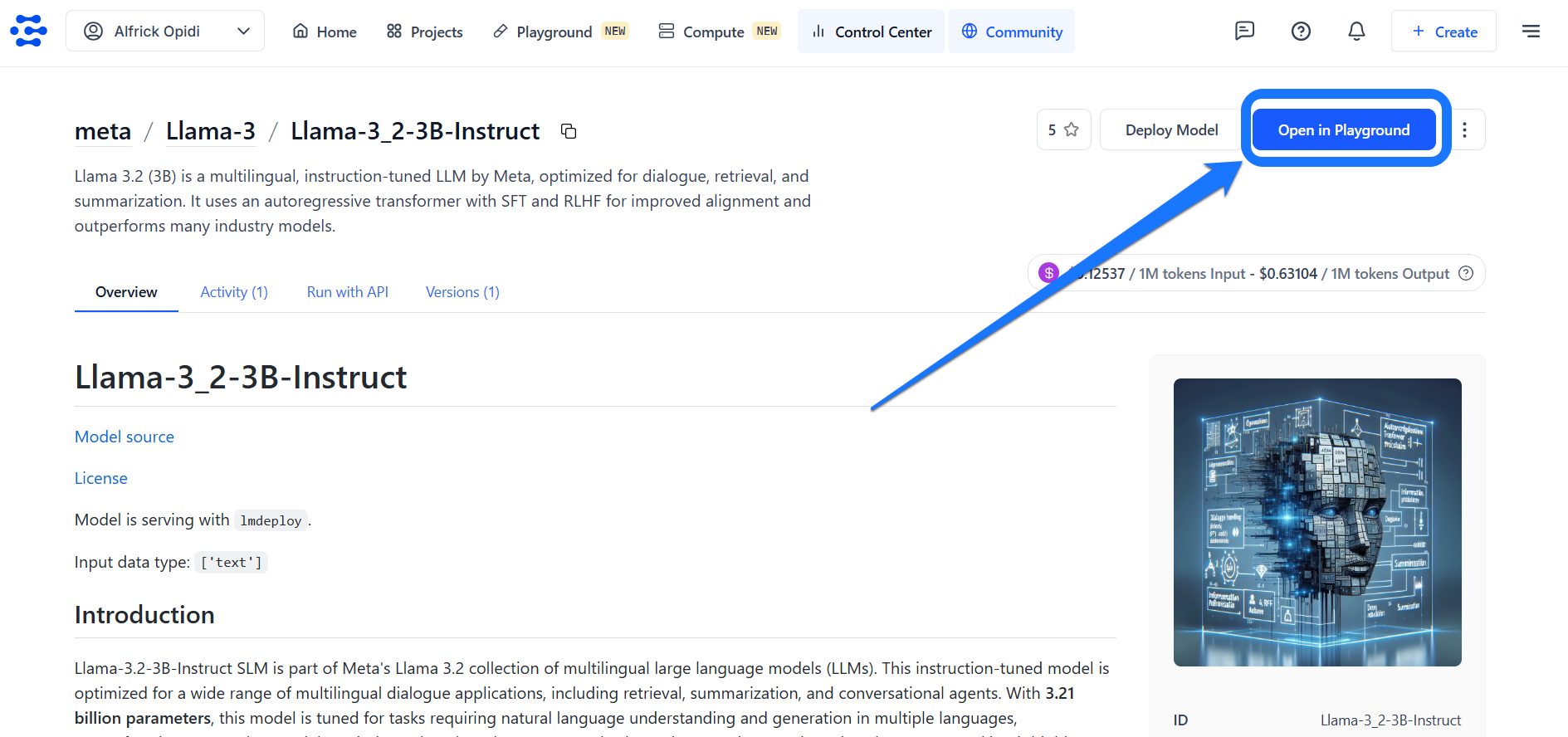
After finding a language model you want to use, go to its individual page and click the Open in Playground button located in the upper-right corner.
For this example, we'll use the Llama-3.2-3B-Instruct model.
Step 2: Run Your Inference
You’ll be taken to Clarifai’s AI Playground — an intuitive interface that lets you quickly run inferences with models and explore the platform’s full capabilities without any additional setup.
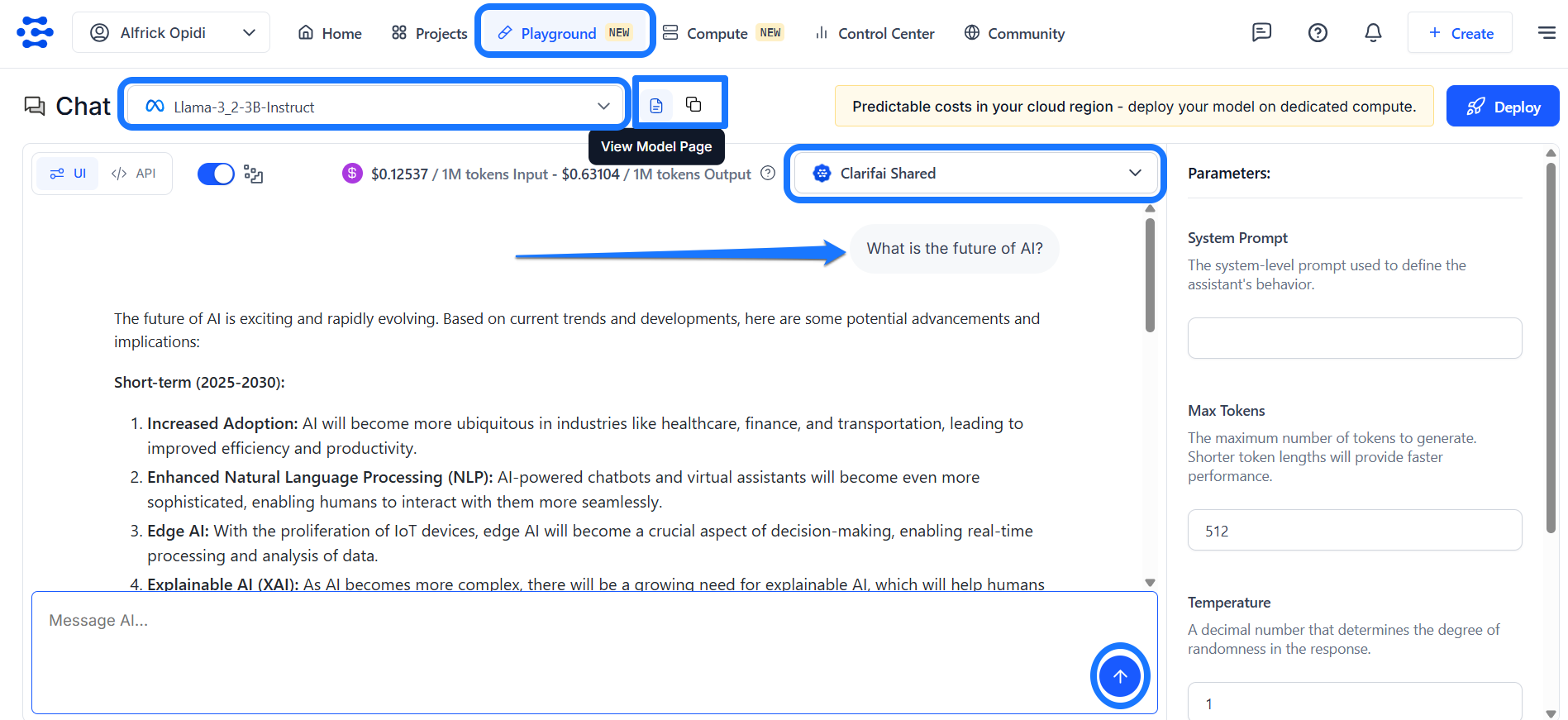
Alternatively, you can access the Playground directly from the top navigation bar. Once inside, use the model selector in the upper-left corner to search and choose the model you want to use for inference.
Note: If you click the View Model Page icon (the file symbol) next to the model selector, you’ll be taken to the model’s individual page, where you can view detailed information about it. Next to it, you’ll find the Copy Model URL icon, which allows you to quickly copy the model’s URL for easy sharing or reference.
In the message box at the bottom of the Playground, enter your desired prompt to generate text using the selected model. You can also choose from the predefined prompt examples provided.
Once your input is ready, click the arrow icon in the message box to submit your request.
The model’s response will stream in real time, allowing you to see the output as it’s being generated — just like a live chat experience. Clarifai’s streaming capabilities allow language models to return responses token by token, enabling natural and interactive conversations.
For these examples, we’re using the default deployment settings (Clarifai Shared) and default inference parameters. You can customize these settings as needed to suit more advanced use cases.
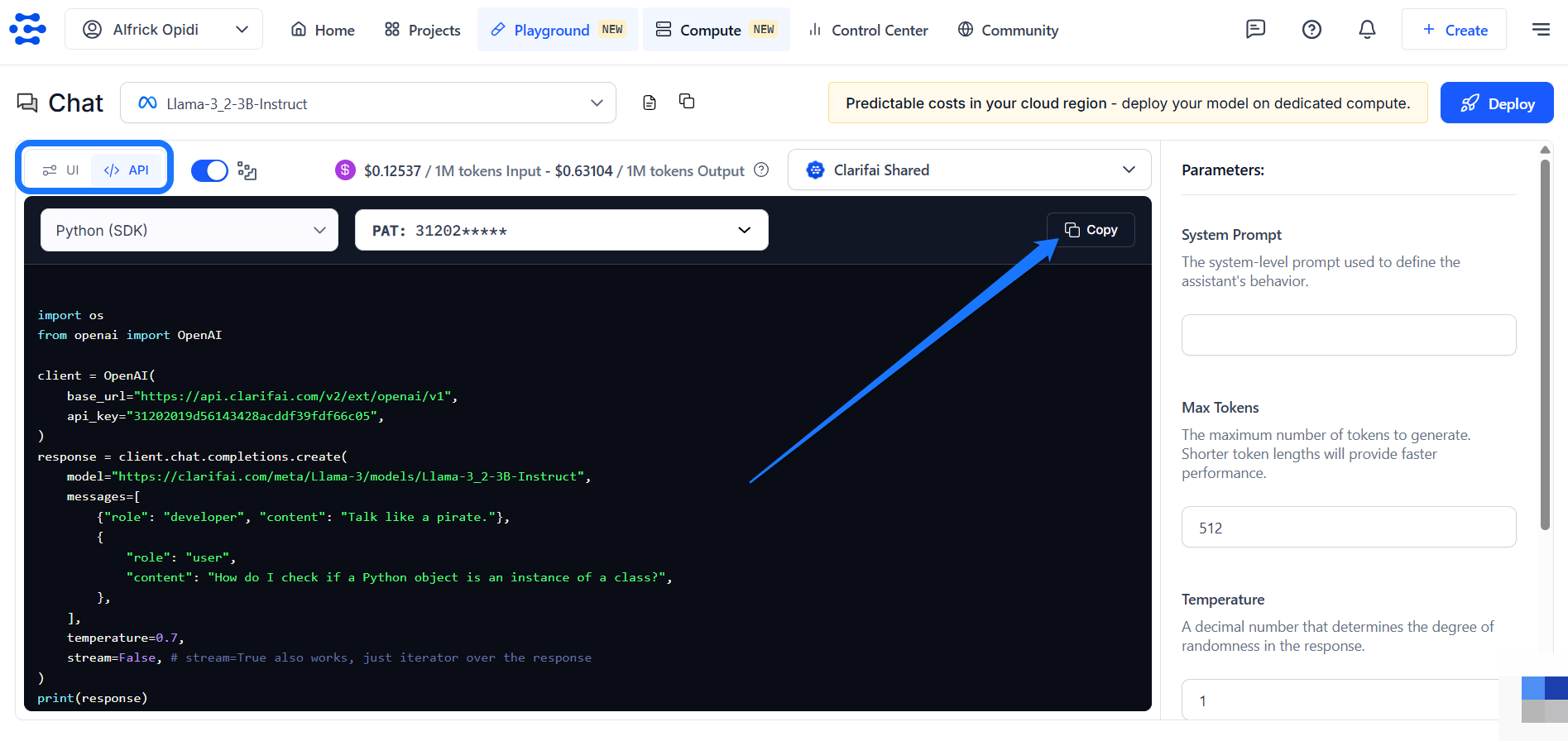
You can also toggle the button in the upper-left section of the Playground to view ready-to-use API code snippets in multiple programming languages — just copy and paste them into your project.
Generate Multimodal Predictions
Clarifai supports multimodal models — models that can process and understand more than one type of input at a time, such as images combined with text. These models are designed to handle complex scenarios where context from multiple input types improves prediction quality.
Their common use cases include tasks like image captioning, visual question answering (VQA), and multimodal classification.
Step 1: Get a Model
After finding a multimodal model you want to use, go to its individual page and click the Open in Playground button located in the upper-right corner, as illustrated earlier.
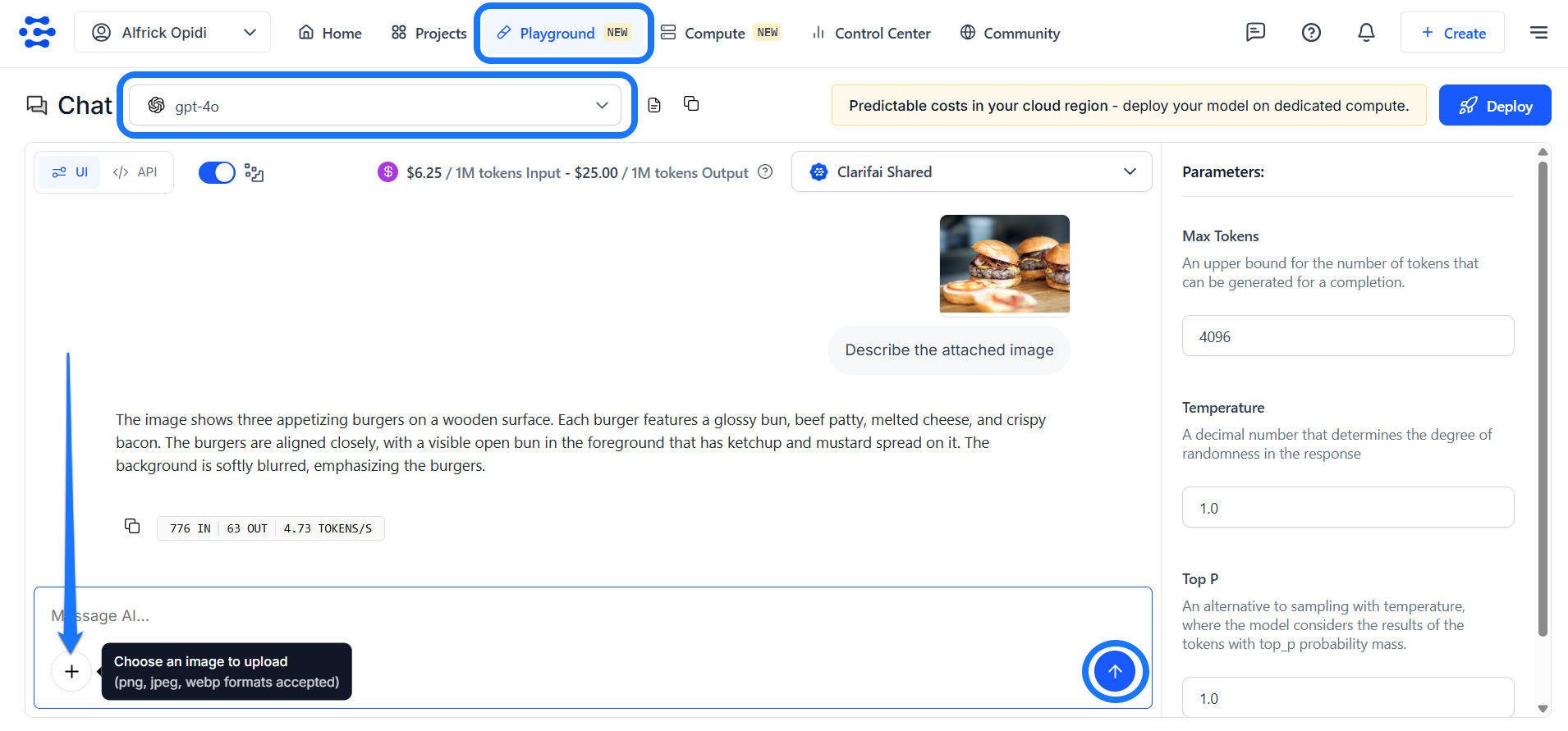
For this example, we’ll use the GPT-4o model, which can process both an image and a text prompt simultaneously.
Step 2: Run Your Inference
While on the AI Playground, navigate to the message box at the bottom and click the plus (+) button. A pop-up window will appear, allowing you to select and upload an image.
Once the image is uploaded, enter your accompanying text prompt in the message box. Then, click the arrow icon to submit your request.
The model’s response will be streamed in real time, allowing you to see the output as it’s being generated.
Generate Visual Predictions
The Clarifai platform allows you to leverage powerful AI models to analyze and understand visual data such as images and videos. By providing visual input, you can prompt a model to analyze the content and generate an output based on its learned visual understanding.
Depending on the model type, the output may include image classifications, object detections, segmentation masks, or even AI-generated visuals.
The Playground automatically detects the appropriate mode based on the selected model — intelligently switching between Chat and Vision modes to match the model's capabilities.
Step 1: Get a Model
After finding a visual model you want to use, go to its individual page and click the Open in Playground button located in the upper-right corner, as illustrated earlier.
For this example, we'll use the general-image-recognition model to identify and classify a variety of concepts in images.
Step 2: Run Your Inference
While on the AI Playground, click the plus (+) blue button on the left side. A pop-up will appear, offering the following options for making predictions:
- Try your own image or video
- Batch predict on app inputs
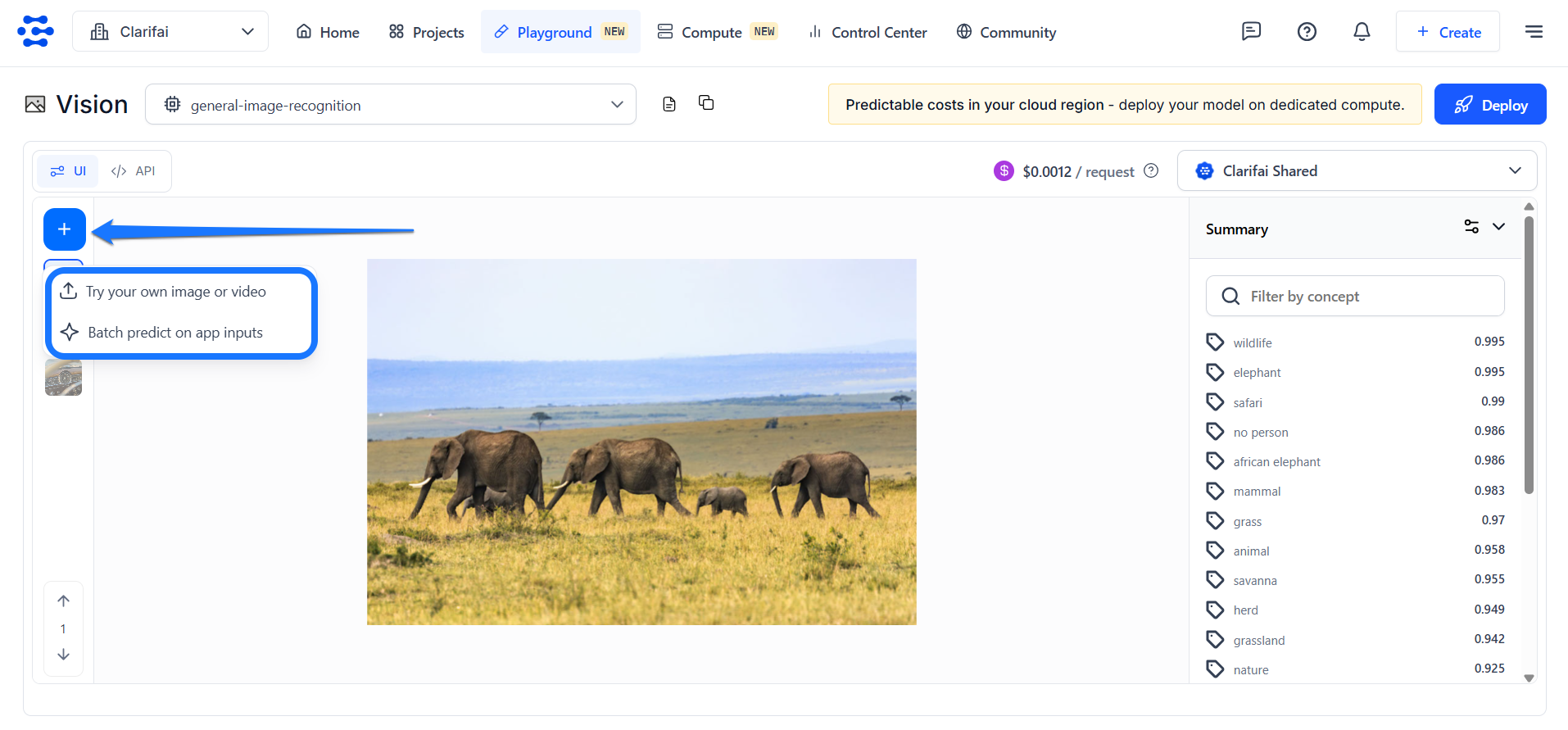
Try Your Own Images or Videos
This option lets you add an input and see its predictions without leaving the Playground screen. If you click the button, a small window will pop up, allowing you to upload your input.
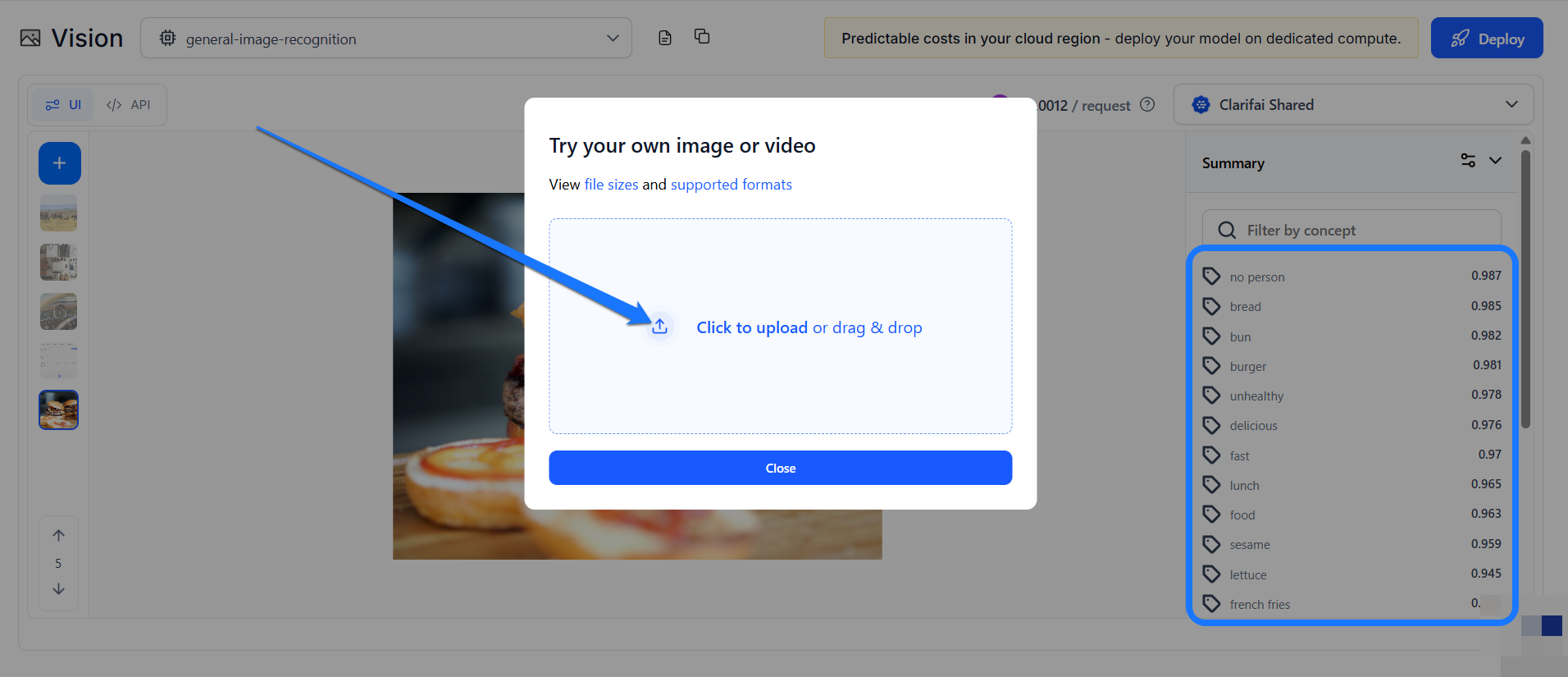
After uploading the image, the model will analyze it and return a list of concepts identified on the right side of the page.
Batch Predict on App Inputs
This option lets you select an app and a dataset. If you click the button, a small window will pop up, allowing you to choose an app and a dataset with the inputs you want to view their predictions.
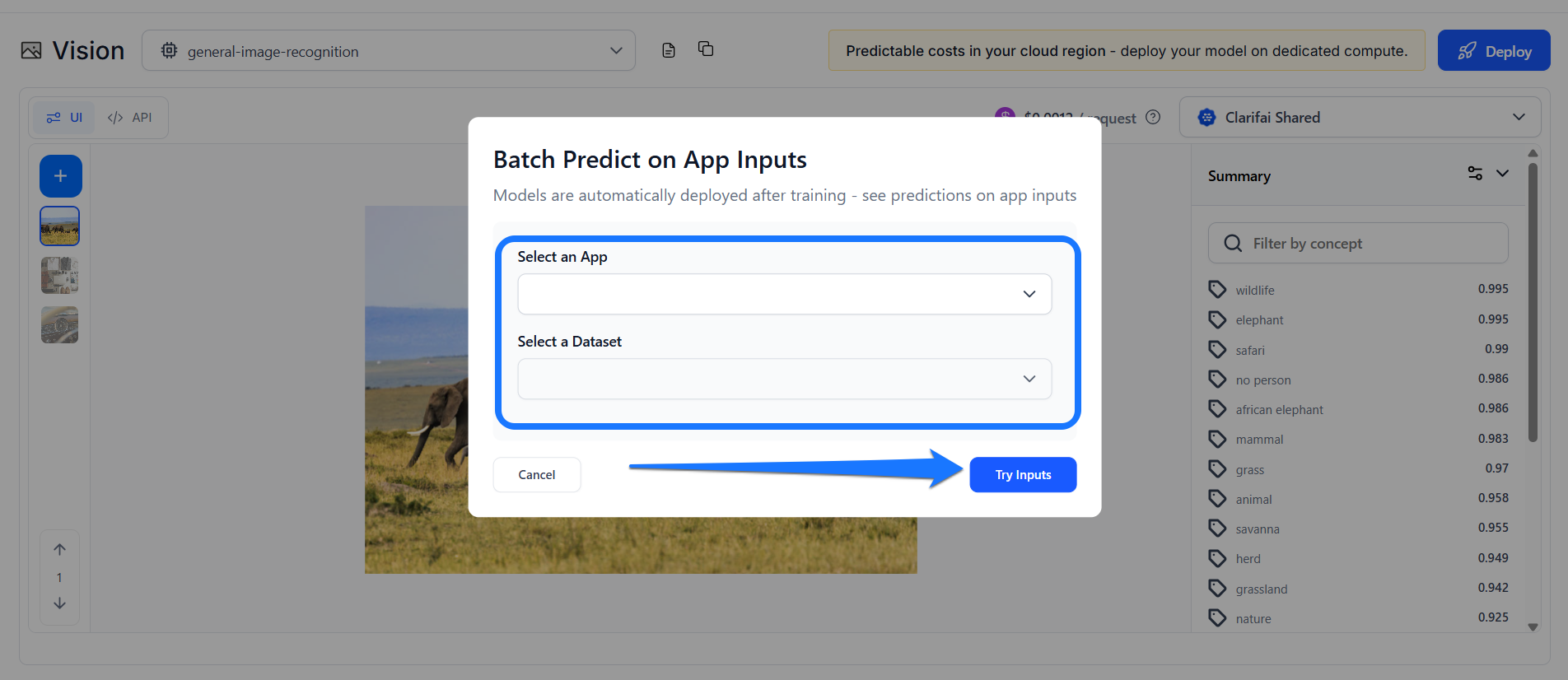
After selecting an app and a dataset, click the Try Inputs button.
You’ll be redirected to the single Input-Viewer screen with the default mode set to Predict, allowing you to see the predictions on an input based on your selections.

Generate Predictions Within Input-Viewer
The single Input-Viewer is the main page that showcases the details of a single input available in your app. If you click an input listed on the Inputs-Manager page, you'll be redirected to the viewer page for that input, where you can view and interact with it.
Step 1: Get a Model
To make predictions on an input within the single Input-Viewer, start by switching to predict mode by toggling the Predict button located in the upper-left corner of the page.
Next, click the Choose a model or workflow button in the right sidebar to select the model you want to use.
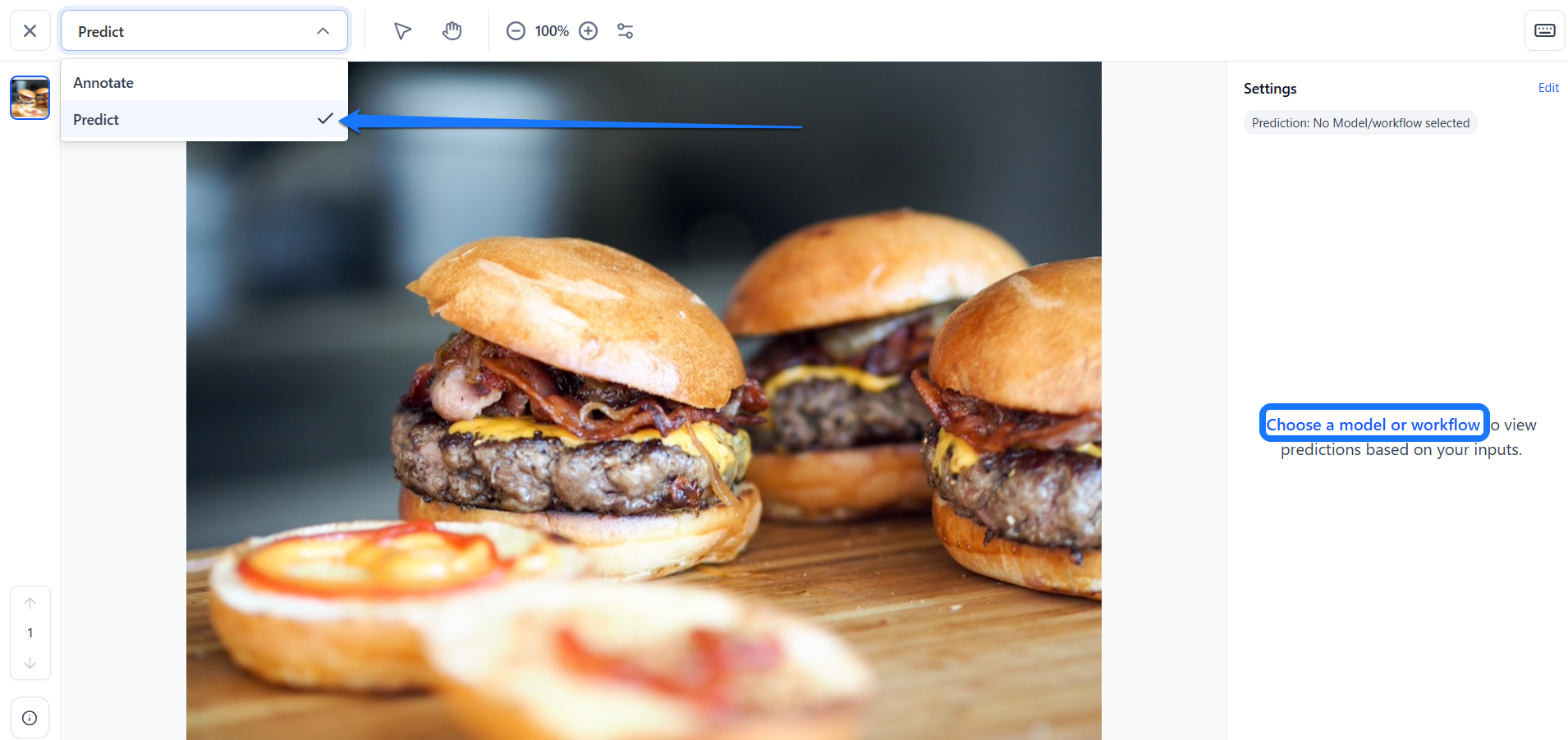
In the window that appears, choose your desired model. You can choose your own customized model or workflow, or look for a public one from the Community platform. You can also create your own model or workflow from there.
To select a public model or workflow from the Community, click the Explore Community Models / Workflows button. In the pop-up window, use the search bar to find the desired model or workflow.
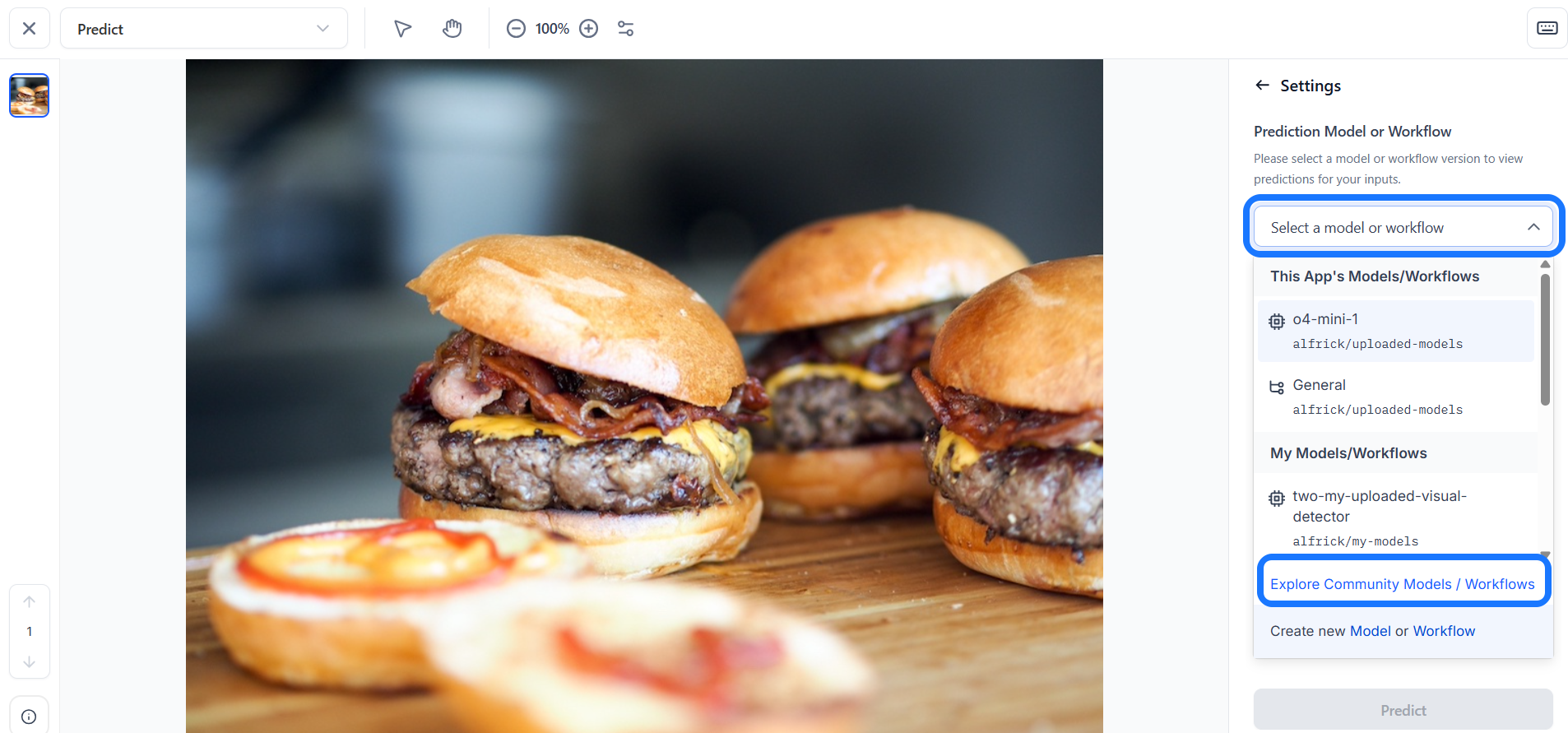
For this example, let’s choose the Community’s Qwen2_5-VL-7B-Instruct model, which is a vision-language model that excels in visual recognition tasks.
Step 2: Run Your Inference
Next, select a deployment from the Deployment dropdown. For this example, we’re using the default deployment settings (Clarifai Shared).
If needed, you can also create a new deployment from this window.
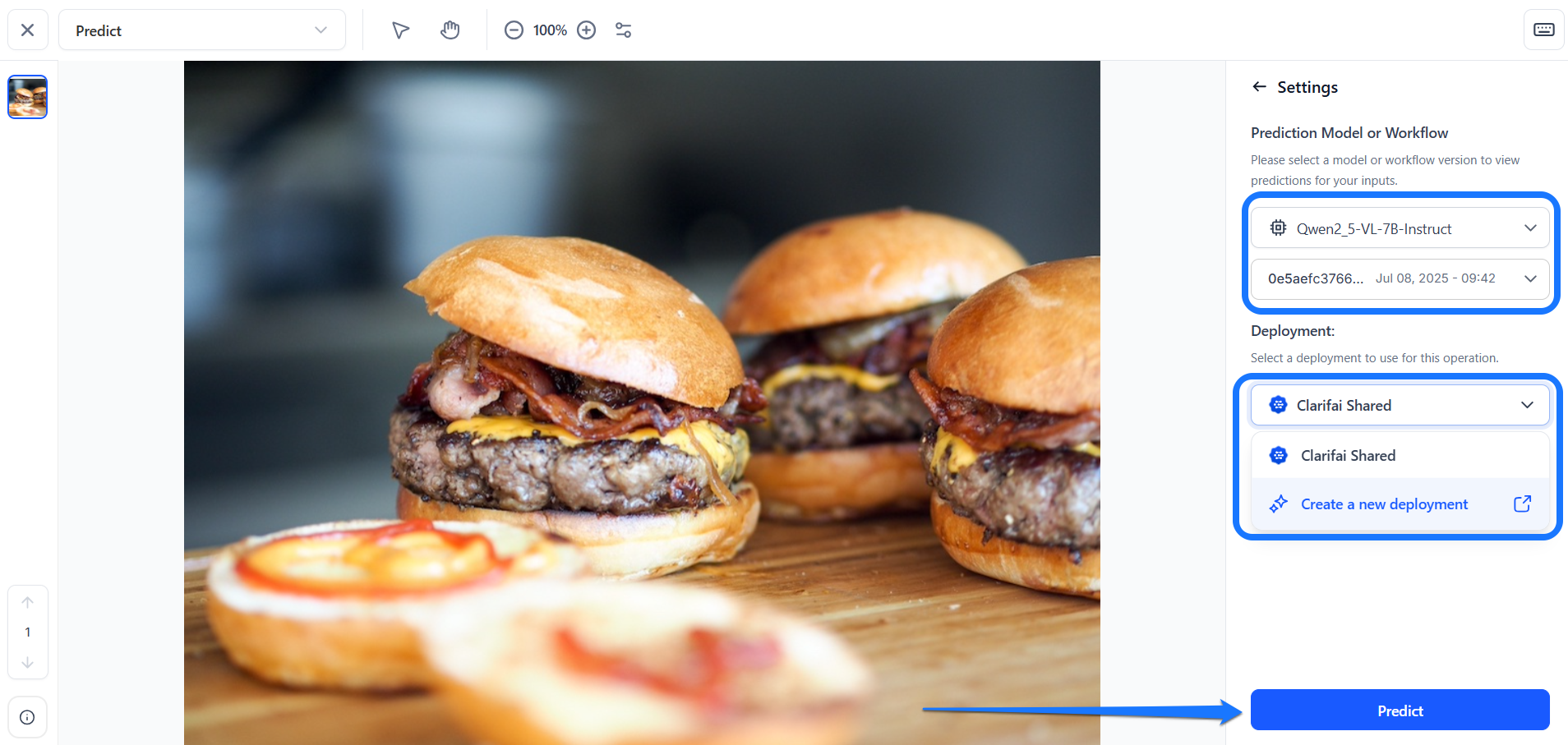
Lastly, click the Predict button at the bottom of the sidebar to start making the predictions.
The model will process the input and return predictions in real time, allowing you to immediately view the results within the Input-Viewer screen.
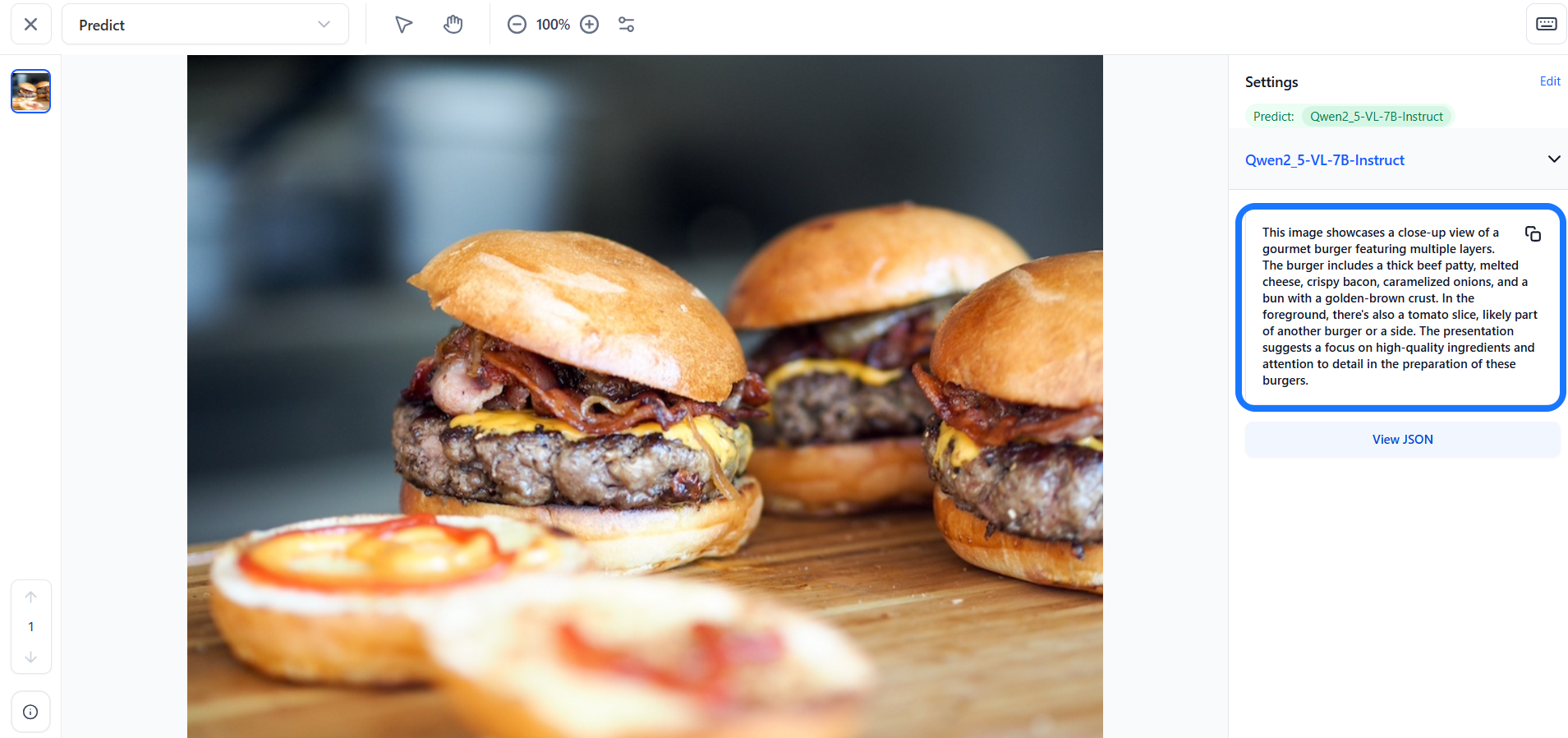
For models that output concepts, the Prediction Threshold slider allows you to control which predictions are displayed by setting a minimum confidence level. Only predictions with probabilities that meet or exceed this threshold will be shown. You can also use the Filter by concept search field to quickly locate specific concepts and view their associated predictions on the page.